Table of Contents
- Data choice-------------------------2
- Background information--------------4
- Data description--------------------5
- Data pre-processing-----------------6
- Data mining-------------------------9
- ZeroR-------------------------------10
- RandomTree--------------------------12
- DecisionTable-----------------------13
- Discussion of findings--------------14
- References--------------------------23
- Appendices--------------------------25
Data choice
In this assignment, a brief data analysis of the selected dataset will be carried out for this task utilizing the WEKA data analysis tool. The features of this WEKA tool for data preprocessing and advanced analysis of the selected problem context are amazing. In the process to improve the efficiency of the analysis process, it is essential to gather and arrange data in the right way at the beginning of this project. The WEKA insightful stage for the most part works with .arff arrangement of information (Li, 2023). The.csv file that contains this dataset was downloaded from the UCI data repository. It is necessary to convert these data into the.arff format. The analytical platform's arff viewer tool makes this simple to accomplish. The various process and steps for transforming data have been shown in this section along with the analysis of the data that is suitable to understand the students’ performance.
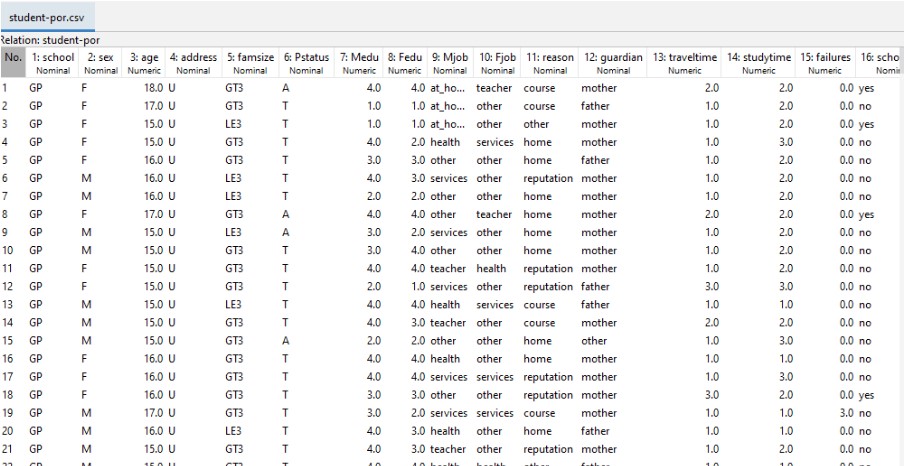
In the above figure, the CSV has been that has been imported into the WEKA has been shown. The image illustrates all the data of the CSV which in order to do the analysis process have to be transformed into the arff file in the next step.
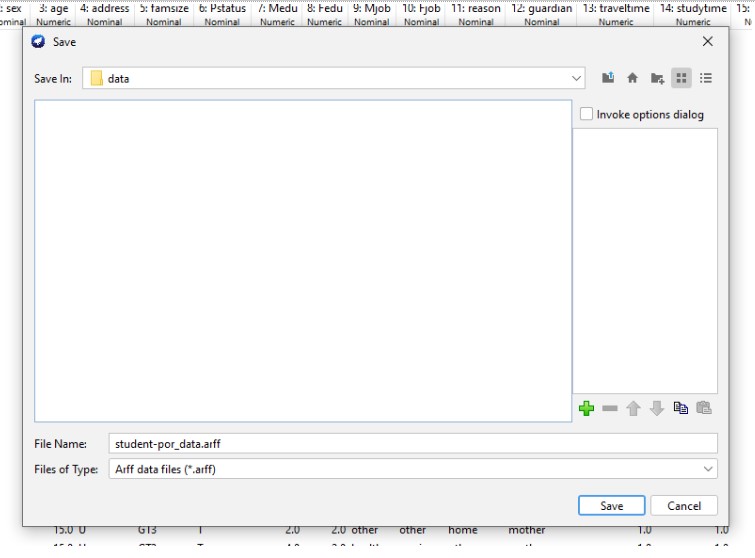
In the above image, the transformation process of the CSV to arff has been shown. The CSV data file has been saved in the format of arff in order to begin the analysis of the data.
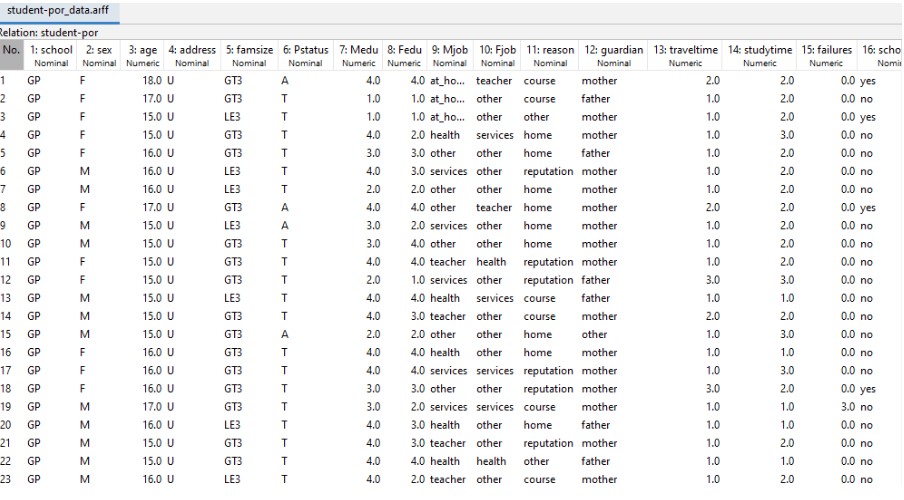
In the above image, the successful complete of the transformation of CSV data set into the arff format has been illustrated and all the data has also been shown.
Background information
"Data mining" is currently a crucial technique in a variety of sectors, notably in the sector of Education. Depending on the circumstances of the issue in question in the sector, specialists in the area use a range of "data mining" techniques (Kara, Fırat & Ghadge, 2020). In this assignment, thorough "data mining" performance is going to be performed in accordance with a particular company's problem. Educational information mining is a developing area of interdisciplinary research that applies Data Mining or DM to the field of education or Educational Data Mining. The program's primary goal is to provide tools for analysing many different kinds of academic information. With the goal to enhance the educational results of students and explain educational proficiency, it seeks to gain a greater understanding ways pupils understand and specify the settings within which they are able to do so. A significant amount of impending knowledge from numerous sources, appearing throughout different arrangements and objective applications can be stored in administrators' education-related information.
In this particular scenario, a collection of academic achievement data has been acquired from the UCI machine learning repository. The data collection is on explores Portuguese language presentations from two different Portuguese educational establishments. The data collection includes several rows that give specific information regarding the pupils. Available credentials include residence, guardians' specifics, family situation, medical issues, focus on support, and many aspects. These qualities are independent and cannot be changed or foreseen. In addition to anticipated contingent variables, subsequently, will be contingent on the variables that are independent. There are several additional attributes can be obtained from the data such as G1, G2, and G3.
Here in the data set, G3 is the combined impact of G1 as well as G2 in this instance. These distinct variables will be taken into account and utilised to anticipate or categorise the parameter of interest. These statistical resources might be used to do a quick analysis of the student's performance. The WEKA analytical tool has a variety of data mining algorithms that are going to be used on the collection of data (Kodati, Vivekanandam & Ravi, 2019). An overall concept for managing and analysing data may be drawn from this project. The educational institution can also implement clear changes to its system or students' educational strategies. However, connections throughout the various sections must be clear in order to alter students' learning processes. Conversely, it is also possible to identify pupils correctly using the circumstances of the observed concern.
Data description
When conducting complete "data mining and analysis" on the chosen data set, it is critical that one possess an in-depth knowledge of the information set. When the analyst is familiar with the data set, it is going to be simpler to explain it through the data analysis platform (Lochmiller, 2021). Subsequently, it is necessary to have a deep comprehension of each characteristic in order to make the greatest possible use of the data set at hand. The chosen data collection has 649 entries roughly spread over 33 columns. There are numerical and nominal variables in the collection of data. The G3 column is the required variable of target in this scenario. The UCI repository includes a detailed description of each data set value. The following portion has examples of a few key characteristics.
- Fjob and Mjob:Both of these credits, which discuss the professional capabilities of guardians, can be thought of as a single unit. The above acquires a key part in the educational standing of the pupils.
- Travel time:Regular travel time has an impact on student achievement. This aspect will additionally have a big influence on how well pupils succeed. As travel time goes up, study time could shrink, therefore might affect academic achievement.
- Study Time:This constitutes one of the most crucial factors to consider throughout the evaluation. With more pupils, every pupil's time for study grows. This optional factor allowed for an analysis of the goal parameter.
- Activity:Whatever extracurricular endeavour helps students improve their presentations in lessons. The chosen data set contains a column for activity. This particular type of trait constitutes a characteristic that stands on its own without comparison.
- G3:The following was considered taken into account as a variable of interest that depends on each of the independent variables. Nevertheless, this grade combines G1 and G2 grades.
Data pre-processing
In this section, the dataset has been entirely converted to an arff format at the project's core level and is supported by the WEKA conceptual step. The imported data set now has to be organised to enable it for it to function for assessment. The logical response after a reliable link of data preparation jobs is the final data set that is able to be seen as accurate as well as helpful for additional mining operations. Data analysis which hasn't been carefully vetted for such shortcomings could lead to false outcomes (Porter & Espeland, 2023). Consequently, before doing an analysis process, it is crucial to take the data’s organisation and correctness into account. The search for data becomes particularly challenging while it includes a lot of duplicated and pointless content. In accordance with the chosen data set, a couple of data handling processes were performed done, as indicated in the following section.
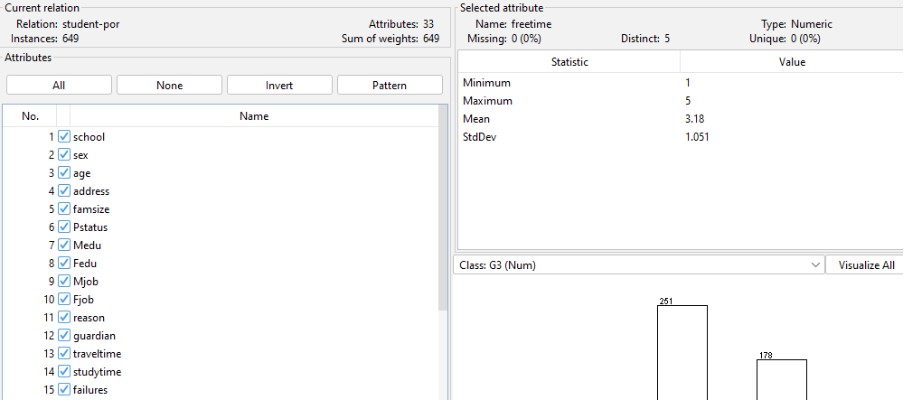
In the above illustration, there are very few entries that have missing attributes. A lack of attributes causes inaccurate outcomes while comprehending the framework. Addressing with the replace of missing attributes in this case via making use of WEKA platforms is crucial (Gong, Guo & Wang, 2023).
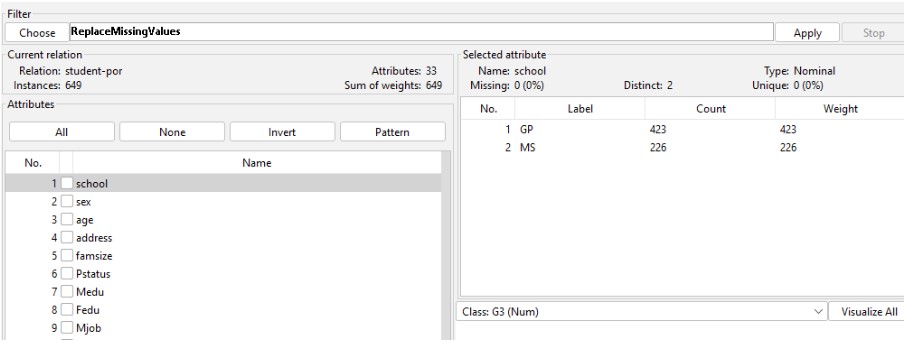
In the above illustration, the "ReplaceMisisngValues" filter has been used to address missing values in each attribute of the data set. After filtering the data set, it could be observed that none of those missing attributes are available.
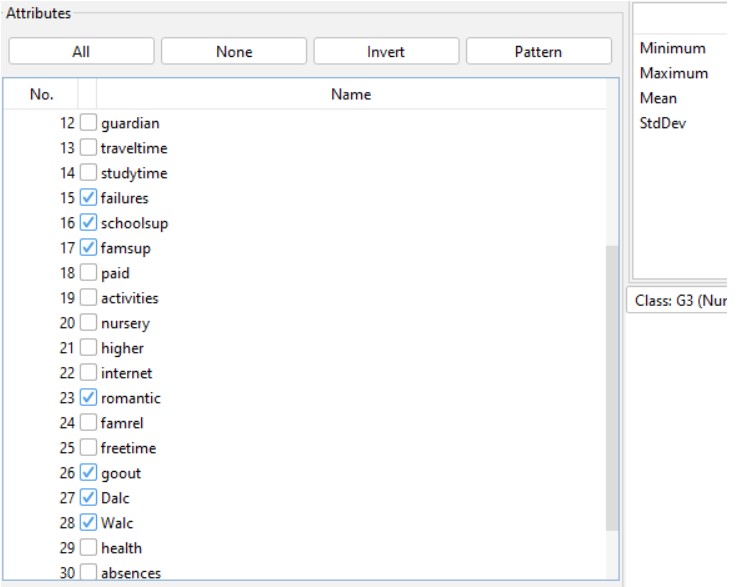
However, a few characteristics do not offer actual insights to handle an important educational and operational challenge (Reinkemeyer, 2020). In order to simplify the research, these attributes might be eliminated from the data set. They include parts like failures, schoolsup, famsup, romantic, goout and others. The recognised parts have been removed from the data set displayed in the image above through the use of the remove option. In the above image, it can be observed that after the removal process only 26 attributes are available once undesired attributes are removed. Currently, additional data evaluation may be easily completed using the areas that are available. This vital data management technique is known as feature engineering.
The importance of choosing proper apparent and quantitative parameters cannot be overstated in order to successfully advocate quantifiable research using the available attributes. In this case, the tool's analysis methods were used to modify the data type for a few features. Different kinds of data pre-handling methods may have been included within the logical process in accordance with the data arrangement of the selected data collection (Abd Alazeez & Thaher, 2021). In a typical supervised educational setting, a prepared data collection is provided with the goal of providing a representation that may be utilised to anticipate unforeseen circumstances. There may be several ways to illustrate this educational calculation. The most common way to accomplish this is to refer to it as a collection of instances, however it's essentially a collection of assets estimates that may include duplicates. Each combination includes a series of an aspect value illustrations. Each integrity has a defined range of possible results throughout beginning the educational process.
Data mining
The main aim of this project is to mine data using the WEKA analytical platform. There are several tactics as well as methods that may be used to perform data mining. An assortment data analysis computations were performed run on the collected data throughout the course of this cycle. In the field of data mining, prediction techniques are frequently considered to be substantial characterizations (Rong, Teixeira & Soares, 2020). It has become common knowledge that controlled techniques attempt to identify relationships between certain illustrates, also known as components or characteristics, and exceptional qualities, also known as classes. A model design serves as a representation of the ideal association.
A framework that particularly tackles and investigates behaviours that are encompassed by the data as well as that, once the quantities of the data characteristics are interpreted, may be used to calculate the value of the desired quality. Classifying calculation is used in numerous fields of application such as finance, health, as well as construction. Several distinct data mining algorithms have been applied to the available information set in this section.
ZeroR
For assessing the outcomes of various educational approaches, the ZeroR data mining method is used. ZeroR consistently selects a category that is well-known. ZeroR data can be utilised to evaluate the effects of various instructors to determine if the results are beneficial, in particular since there has been a single, large, predominating categorization. The vital information may be seen as a concrete instance, and the configurations are referenced as subcategories (Namoun and Alshanqiti, 2020). The event's rewards might be characterized by a variety of characteristics. Subsequently, it is possible for these attributes to be real, conceptual, computational or theoretical. The ZeroR layout strategy has also been used in this task, employing the provided informative database.
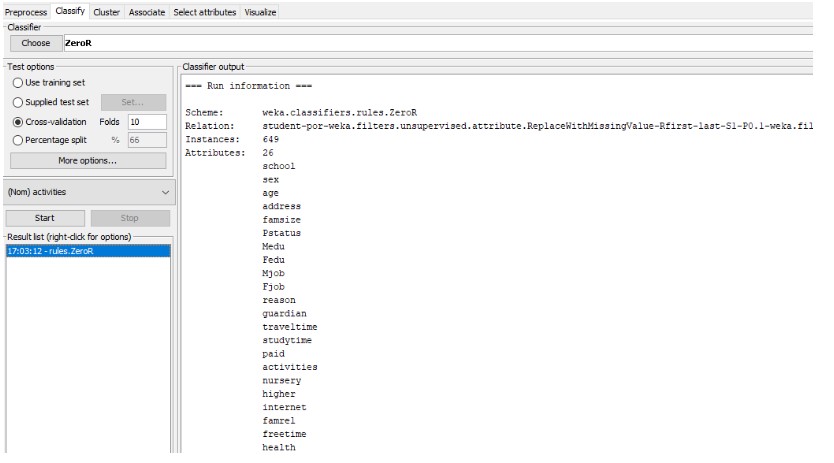
In the above image, the ZeroR algorithm analysis has been implemented on the chosen data
set. The image shows the successful implementation of the ZeroR algorithm on the attribute
column of activity of the chosen data set to analyse the students’ performance in the
Portuguese language.
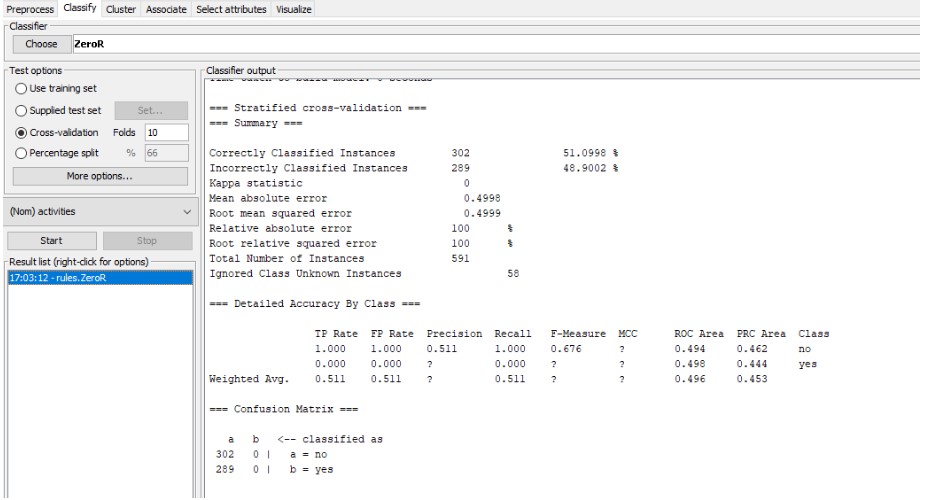
In the above image, the successful implementation of the ZeroR algorithm has been
illustrated. With the accurate classification of 51% the ZeroR algorithm has been able to
produce the final result. The confusion matrix of the algorithm has also been shown in this
image.
RandomTree
For assessing the outcomes of various educational approaches, the RandomTree data mining method is used.
In the above illustration, the RandomTree algorithm analysis has been implemented on the chosen data set. The illustration above shows the successful implementation of the RandomTree algorithm on the attribute column of paid of the chosen data set in order to analyse the students’ performance in the Portuguese language.
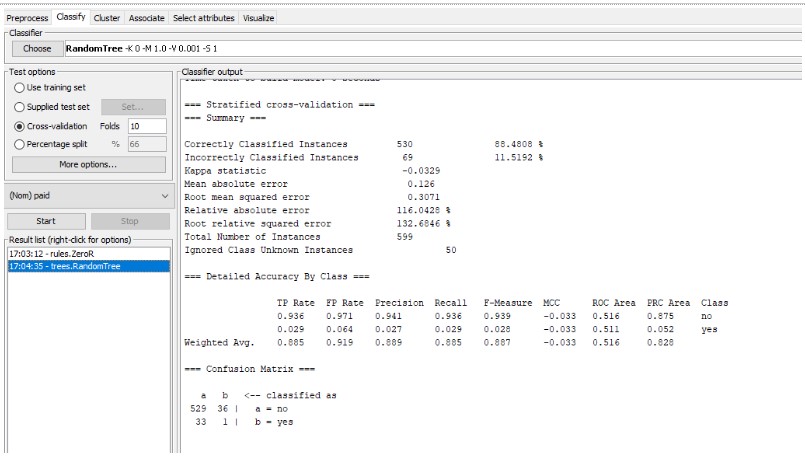
In the above image, the successful implementation of the RandomTree algorithm has been illustrated. With the accurate classification of 88% the RandomTree algorithm has been able to produce the final result. The confusion matrix along with the detailed accuracy by class of the algorithm has also been shown in this image.
DecisionTable
For assessing the outcomes of various educational approaches, the DecisionTable data mining method is used.
In the above illustration, the DecisionTable algorithm analysis has been implemented on the chosen data set. The illustration above shows the successful implementation of the DecisionTable algorithm on the attribute column of Pstatus of the chosen data set in order to analyse the students’ performance in the Portuguese language.
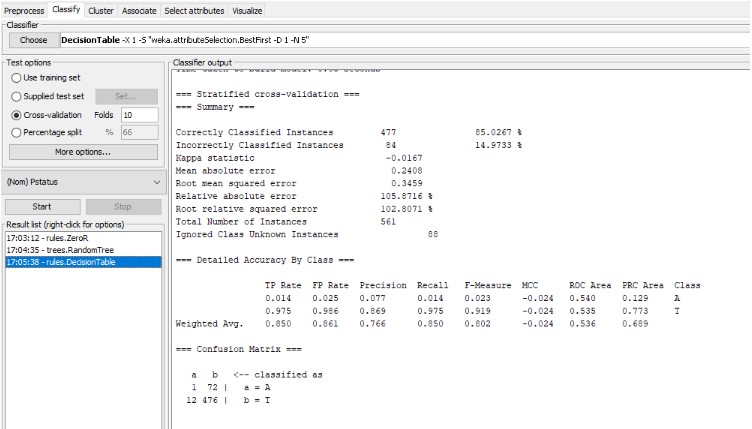
In the above image, the successful implementation of the DecisionTable algorithm has been illustrated. With the accurate classification of 85% the DecisionTable algorithm has been able to produce the final result. The confusion matrix along with the detailed accuracy by class of the algorithm has also been shown in this image.
Discussion of findings
In this section, various visualisation that will provide valuable insights regarding the students’ performance in the Portuguese language.
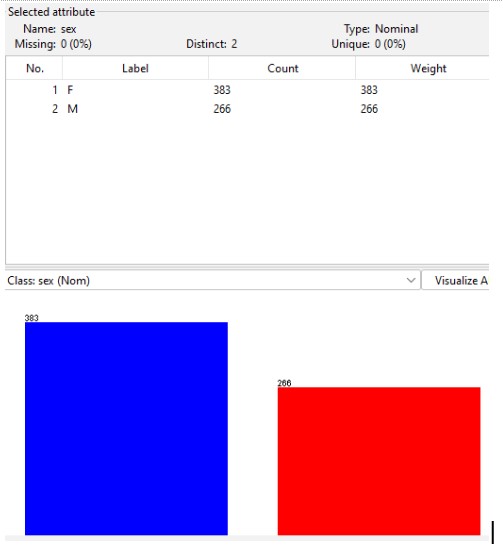
In the above illustration, it has been shown that the female students performed better in comparison to the male student.
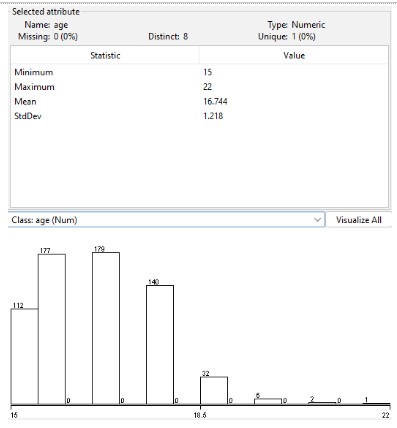
In the above illustration, it has been shown that the age group of the successful students are from 15 to 18 who performed better,
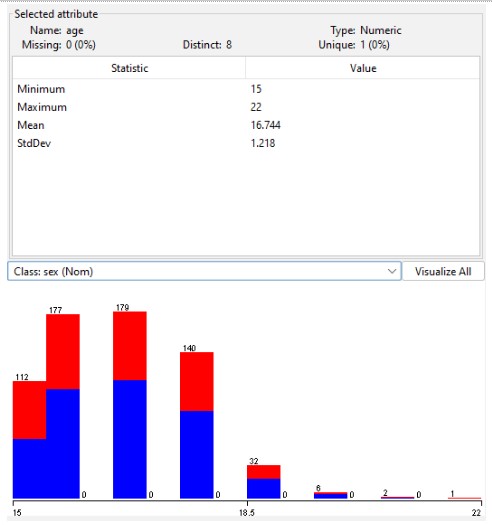
In the above illustration, the graph was developed in consideration of the gender of the students. In every age group, there are more female students in comparison to male students.
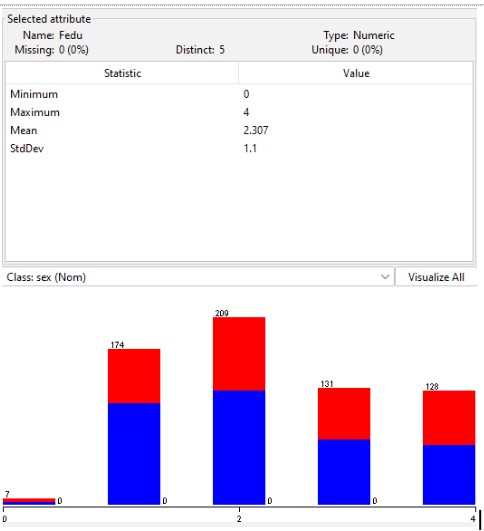
In the above illustration, the graph was developed in consideration of the father’s education of the students. In graph, it has been illustrated that most of the fathers are educated which holds an essential part in the good performance of the students.
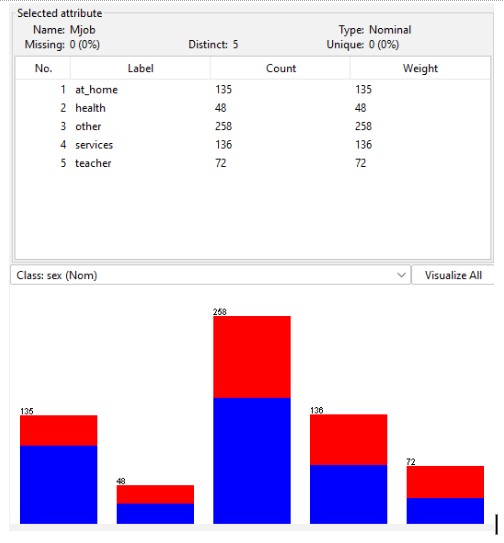
In the above illustration, the analysis was carried out to determine the mother's line of work. There are more people working in the services and other career profiles.
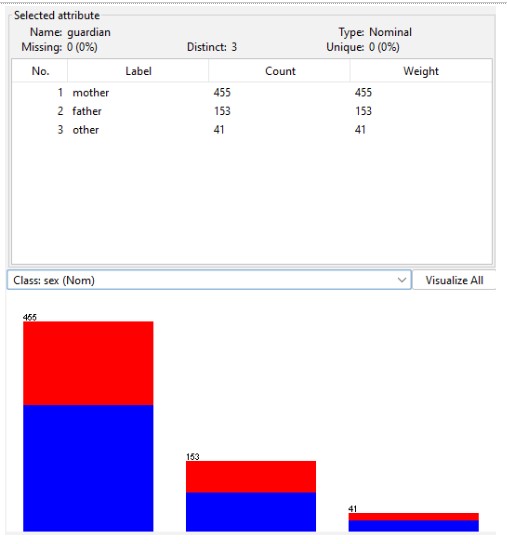
In the above illustration, the graph was developed in consideration of the guardians of the students. In graph, it has been illustrated that mostly mothers are the primary guardians who holds an essential part in the good performance of the students.
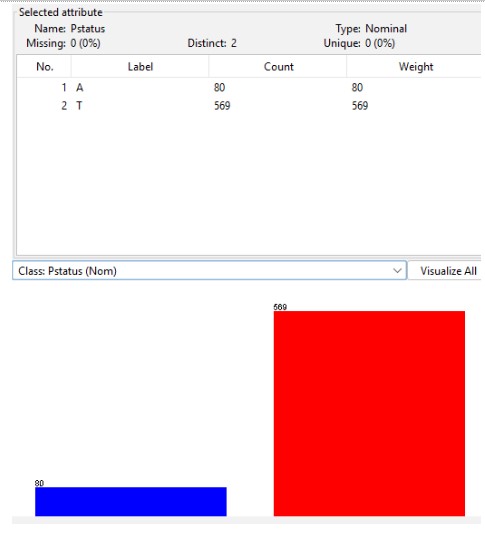
This entails yet another crucial analysis that aids in tracking student success in the classroom. The fact that most parents live together is a significant factor in how well students succeed.
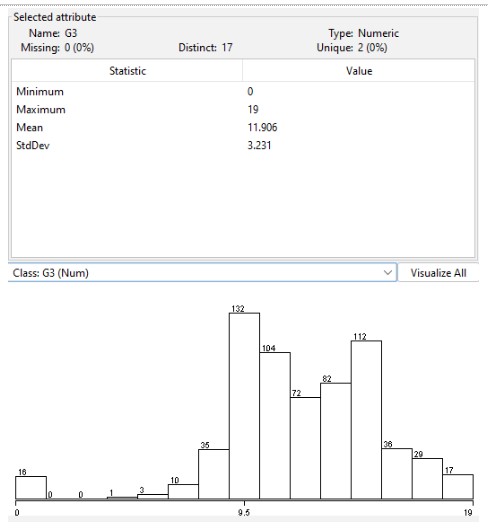
The goal parameter was successfully visualized at the result. The combined G1 and G2 grade yielded the last result. This parameter G3 has undergone a critical independent variable analysis. All relevant data mining tasks and their outcomes have been included in this assignment, according to the requirements of the institution.
Appendices
Data source: